Input Connectors
Supporting a variety of different data sources, including:
• Amazon S3 Bucket
• Amazon Firehose
• Text-based Stream Data
• Syslog
• Splunk TCP Stream
• AText-based files
• And other major source data providers

Those of us who need to use the data today, need data scientists, engineers, architects, and a large infrastructure of data warehouse / data lake to support it. We aimed to eliminate these by reducing the complexity of all of the technical facets of data operation, down to a single platform that supports it all, and give you the data when you need it, at the time you need it.
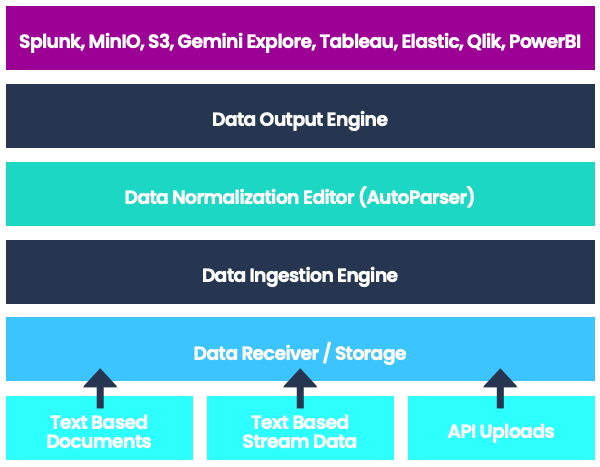
Data is an ever growing asset in the corporate world today, and increasing exponentially on a daily basis. Gemini Stream revolutionizes the way you structure and eliminate the unnecessary data from your raw, unstructured data stream with our intuitive no code design which not only helps you gain more insights to your data, but also reduce the need of excessive backend storage to handle all the junk data – by saving you up to 50% of the backend cost!
Supporting a variety of different data sources, including:
• Amazon S3 Bucket
• Amazon Firehose
• Text-based Stream Data
• Syslog
• Splunk TCP Stream
• AText-based files
• And other major source data providers
Build from the ground up for fast data ingestion & parsing purpose
Up to 5 times the speed in data ingestion / parsing comparing to other competitor
Combined with Auto Parser, it can greatly reduce the need for you to worry about your data feeds, ever again.
Machine Learning based pattern recognition system
First of its kind graphical parser system Eliminate the need of programming languages
Data can be manipulated / filtered / masked within the same interface
Intuitive graphical interface assists regular user to deal with data parsing tasks
Built-in compressed storage with less burden on hardware requirements
Automatic clustering capability that can utilize all hardware resources for all computational / storage purpose
• Syslog
• Elastic Index
• Splunk
• Hadoop
• Amazon S3
• Qlik
• PowerBI
• Tableau
With “No Code” data parsing, data fields will be recognized automatically and data normalization rules could be done with ease.
Reduce efforts incredibly by up to 60% of the time spent for data analysts and users working on any data parsing projects
Spend less time waiting for data collecting because of high throughput and high performance data processing engines
Filter out unnecessary data and increase the density of valuable data with high efficiency compression to dramatically save storage space
Specify which data should be masked, and in which way, to prevent sensitive data to be leaked and the privacy breached during analysis
© 2023 Gemini Data. All rights reserved.